多人实时协作是石墨文档吸引人的一大特性之一。使用石墨文档,你可以和同事、朋友同时编写一篇文档或表格,每个人的修改都会实时的同步给其他人。你可以看到每个人光标的跳动,每一个键入的文字。一篇篇运营文案、一份份产品头脑风暴,伴着一杯杯茶与咖啡,就这样在石墨文档上诞生了。
美好的事物背后总是充满艰辛。在技术实现上,多人实时编写会造成许多的冲突,拿表格来说,当用户 Bob 在 B2 单元格编写内容的时候,他的朋友 Jeff 在 B 列的前面又插入了一列,如果两个操作同时发给服务器就会产生冲突。在石墨文档,我们维护了一个数据计算集群通过一套算法计算分析来帮助用户解决冲突。如上面提的例子,最终 Bob 在 B2 单元格编写内容的操作经过服务端的计算会被 transform 成在 C2 单元格的操作发给 Jeff。
 为了尽可能地降低多人实时编写的时延,我们付出了非常多的努力来使得这套算法能够在符合语义地解决编写冲突的前提下尽可能地高效。数据统计表明,在石墨文档有将近 90% 的冲突数据计算可以在几毫秒的时间内运算完成。成就这瞬息时间的功臣之一,就是我们这套算法的一个基本原则:运算耗时仅和操作本身相关,与文档(或表格)原始内容大小无关,换句话来讲,就是算法的时间复杂度不能和原始内容大小正相关。
为了尽可能地降低多人实时编写的时延,我们付出了非常多的努力来使得这套算法能够在符合语义地解决编写冲突的前提下尽可能地高效。数据统计表明,在石墨文档有将近 90% 的冲突数据计算可以在几毫秒的时间内运算完成。成就这瞬息时间的功臣之一,就是我们这套算法的一个基本原则:运算耗时仅和操作本身相关,与文档(或表格)原始内容大小无关,换句话来讲,就是算法的时间复杂度不能和原始内容大小正相关。
这个基本原则来源于我们对用户体验的直觉感知:随着用户在一篇文档或表格中不断地编写,数据同步的速度不应该随着内容的增多而不断变慢,否则使用者对写作体验的好感会逐渐降低,最终导致用户慢慢倾向于尽量少地在石墨文档上编写内容。
去年 12 月,石墨文档正式对外发布了表格公测版。在上线了一段时间后,表格的性能问题逐渐引起我们的重视。当在表格选择一个范围后,设置表格属性(如对齐方式、字号等)后,程序会为范围内的每个单元格创建一个数据对象来记录这些数据。如果选择的范围很大,数据对象就会变得非常多,影响了网络传输和算法计算的速度。
为了解决这个问题,我们决定引入 Range 的概念来将这些拥有同样属性的邻近单元格通过一个范围矩形来表示。如为 B2-C4 单元格设置了文本右对齐格式,之前的表示方法为:
{
B2: { attributes: { align: 'right' } },
B3: { attributes: { align: 'right' } },
B4: { attributes: { align: 'right' } },
C2: { attributes: { align: 'right' } },
C3: { attributes: { align: 'right' } },
C4: { attributes: { align: 'right' } }
}
而通过 Range 来表示则为:
{
RANGE: {
start: 'B2',
end: 'C4',
attributes: { align: 'right' }
}
}
可见使用 Range 来表示表格内容能够使数据的存储更为精简,这样既降低了网络带宽开销,也相应地提高了计算的性能。
确定目标后,问题就被归结为“寻找一个矩阵中的最大公共属性子矩阵”这样清晰的算法逻辑了。
由经验可知,实现寻找最大公共矩阵的目标算法的最佳时间复杂度应该是 O(M*N),因为无论漏掉矩阵中的哪一个元素,都无法确保找到的矩阵是最佳方案。另一方面,与这个问题非常接近的经典算法 Largest Rectangle in Histogram,其时间复杂度为 O(N)。所以我们这里可以进一步地将算法归结成寻找 M 次直方图中的最大矩形,如下图所示。
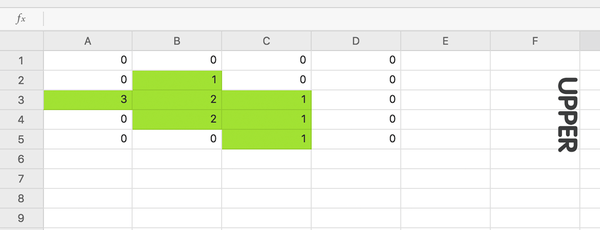
以 A1-D5 为矩阵边界,我们从 D 列开始开始对每一列计算直方图的最大矩阵,其中图中的“upper”为直方图的上部方向。对于每一列,我们使用一个长度为 N (如果使用 Sentinel 来避免边界计算的话则为 N+1)的 cache 数组来存储当前列的直方图高度,即其右侧连续公共属性矩阵的长度。拿 B 列举例,其对应的直方图为:
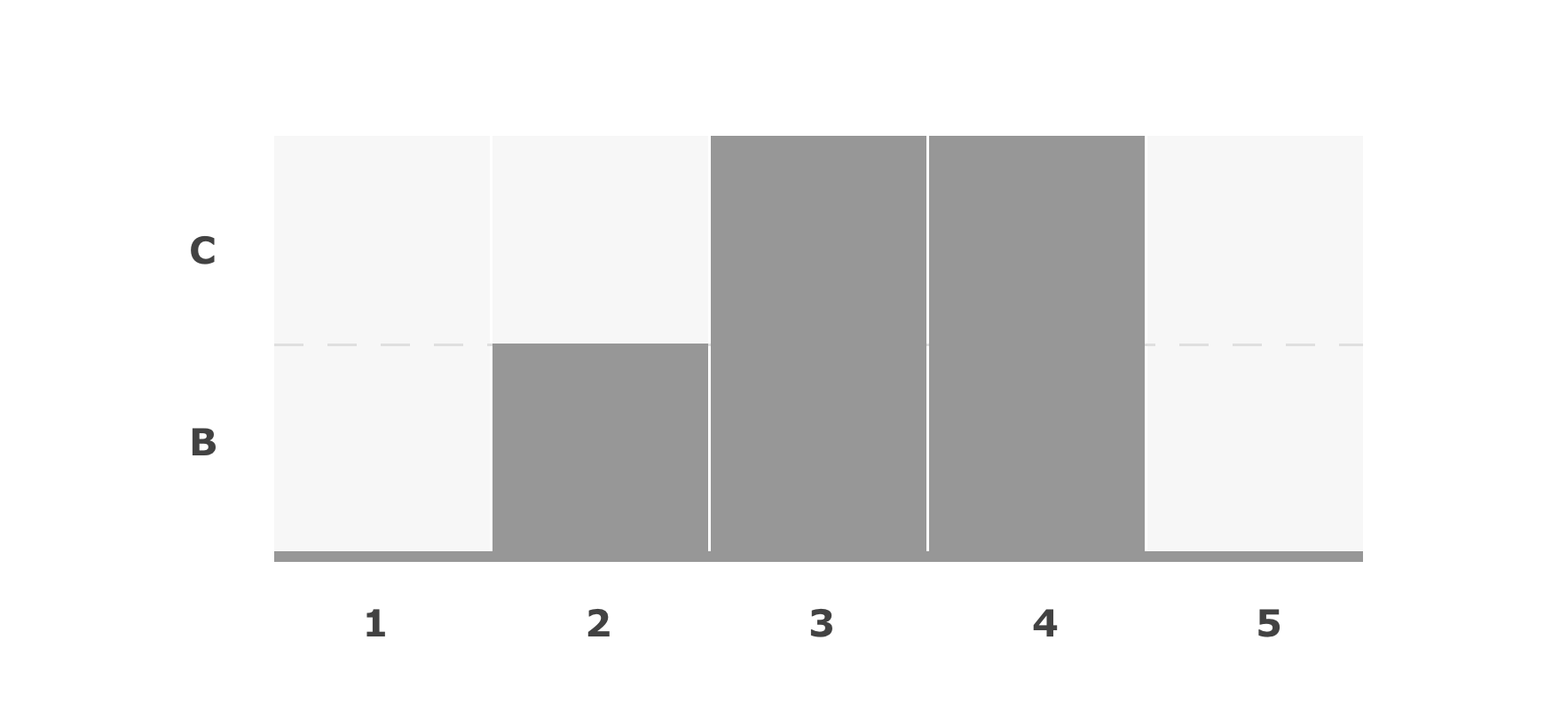
可以看出,B 列最大的矩阵是由第三行和第四行组成的面积为 4 的方形。实际计算时可以通过维护一个堆栈来存储递增的直方柱高度,y遍历一次找出最大的矩形,具体细节可以参考相关的算法资料。对每列进行同样的计算,我们最终可以得出最终的结果。
然而这种算法虽然能够在功能上解决我们的需求,但是其却违背了我们上述提到的算法的基本原则——每次用户的修改,即使只更改了一个单元格,因为有可能会把得到的最大矩形破坏掉,所以我们也不得不对整个表格进行重新运算。
为了能够解决这个问题,我们支持了一个表格存在多个 Range 的结构。在上述算法的基础上,我们定义了一个候选矩阵阈值,每当发现一个矩阵得分超过阈值时,就将其加入一个列表中。阈值的大小取值与表格本身的大小(因为表格数据结构本身缓存了自身的大小,所以这里并不违反“基本原则”)相关,基于我们根据生产环境中的数据计算出的经验公式呈正相关关系。加入列表的时候,因为当前的矩形可能和列表中已经存在的矩形重合,重合的面积就是当同时保留这两个矩形时所浪费的面积,我们称之为冗余面积。我们同样给出了一个经验公式来根据这个冗余面积对新加入(或已存在)的候选矩形进行取舍,宏观来讲即是当候选矩形面积越大、冗余面积越小时就更倾向于保留两个候选矩形,反之则倾向于舍弃一个候选矩形。
接下来,当用户对表格做了修改时,我们不再对整个表格进行重新计算了,只需要对 Range 列表进行一些更新。根据修改位置和原先存在的 Range 中的每个矩形的关系,分为如下几种情况:
如下图所示:

对于第一种情况,则判断用户修改的矩形是否达到了候选矩阵阈值,如果达到了则加入 Range 列表中,否则就以单元格的形式存储。
对于第二种情况,则判断有没有新形成一个更大的矩形(根据坐标进行简单运算即可,是一个 O(1) 操作),如果有则更新原矩形,否则就以单元格形式存储用户的修改。
对于第三种情况,用户的修改会将原来的矩形打散成几个部分,这时会具体分析打散后的每个矩形是否达到候选矩阵阈值,如果达到则放入 Range 中,否则就将改矩形转存成单元格的形式。
可想而知,随着用户修改的增多,原有 Range 中的矩形会不断地被打散,导致越来越趋近于候选矩阵阈值;同时多次增加小的矩形即使最终组成了符合阈值的矩形,也因为没有全局遍历导致无法识别。以上两种情况共同导致了 Range 的碎片化。
针对碎片化的问题,我们为每个表格增加了 fragment 参数记录了当前表格的碎片化程度。每次有针对单元格的操作和行列变换时,就会更新 fragment 的值(实际上,单元格操作和行列变换对 fragment 值的影响并不相同,行列变换时如果命中 Range 中的很多矩形,我们会将 fragment 值进行更大幅度的提升)。当 fragment 达到临界值时,我们会重新跑一次算法来对表格数据进行一次全盘压缩,并重置 fragment。
现在,我们只剩最后一个问题了。那就是尽管我们对表格压缩算法做了精细的优化,实际压缩起来,面对有几万个单元格的大表格来说,压缩一次也要消耗十几毫秒左右。而且一般来说,越大的表格,其协作频率越高,即 fragment 越容易达到临界值,也导致了压缩的频率会更高,从而对服务器的压力也更大。
当多个人编写同一份表格时,每个人拿到的表格数据都是完整且最终一致(约几十毫秒的时延)的。根据这个背景,我们在工程层面对大表格的碎片问题进行了进一步地解决:多个人同时编写表格时,每一个用户都会内置一个碎片计数器并以固定的相位差来定时在浏览器端计算候选矩阵列表,然后和当前服务器版本的结果比较,并在下次向服务器发送本地修改时附带比较的结果。服务器端会根据这个结果相应地调整表格的 fragment 值。对于大表格而言,用户操作的频率虽然会相对更高,但是因为往往都是在已经规范好格式的表格中进行编写的,所以导致的碎片程度反而会比较低。使用这种方法使得服务器只需要在必要的时候才重新计算 Range;并且由于在浏览器端使用了 Web Worker 进行计算,用户实际的表格编写体验并不会受到影响,反而降低碎片整理频率最终能给用户带来更好的编写体验。
石墨文档技术部是一个有趣的团队,我们热衷于尝试新技术,思考新方向,探索一切可以为目之可及的世界增添色彩的方法。欢迎加入我们来一起改进身边人的文档编写体验,经历人生中的下一场波澜!
[北京/武汉] 石墨文档 做最美产品 - 寻找中国最有才华的工程师加入
原文来自:石墨文档技术酒馆
声明:所有来源为“聚合数据”的内容信息,未经本网许可,不得转载!如对内容有异议或投诉,请与我们联系。邮箱:marketing@think-land.com


 分享
分享

基于大模型能力构建的文本审核服务,能够高效精准地识别各类文本违规内容。与传统文本内容安全审核方案相比,具备更强大的语言理解与分析能力,能精准识别复杂、隐晦的违规内容,突破了传统模式的局限。
基于图片审核大模型服务,能够全方位识别图片中的色情、性感、涉政、暴恐、违禁、宗教、引流广告、不良等违规内容,并支持返回大模型的审核结果。结合大模型和专家小模型,提供更细粒度的标签(如色情细分、具体行为、特定物体等),识别范围更广、标签更丰富。 综合效果最佳,适合对误判率、漏判率都有较高要求的场景。
针对AIGC场景,检测AIGC生成的图片是否存在违规或者不宜传播的内容。建议AIGC生成的图片都进行该项检测。
检测图片是否疑似由AI生成合成、图片是否含有AI生成合成隐式标识(如果有隐式标识时支持返回图片AIGC元数据信息)。
根据身份证/手机号进行核验号码是否有涉险诈骗风险。

 苏公网安备 32059002001776号
苏公网安备 32059002001776号


